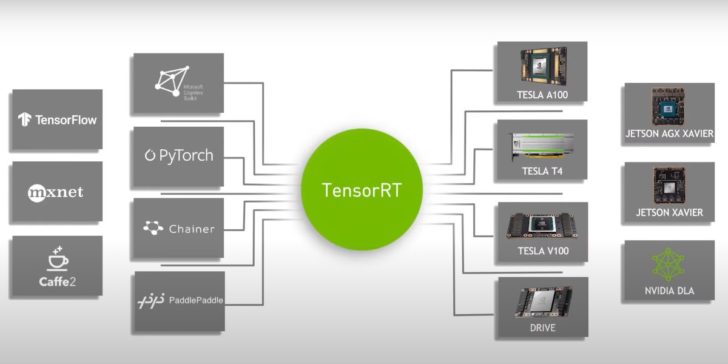
TensorRT 8 es la octava iteración del popular software de IA de NVIDIA que se utiliza para la inferencia de aprendizaje profundo de alto rendimiento. El software combina un potente optimizador de aprendizaje profundo con un tiempo de ejecución que ofrece inferencia de baja latencia y alto rendimiento para una serie de aplicaciones de IA.
La inferencia es un aspecto importante de la IA. Mientras que el entrenamiento de la IA se refiere al desarrollo de la capacidad de un algoritmo para comprender un conjunto de datos, la inferencia se refiere a su capacidad para actuar sobre esa información e inferir respuestas a consultas específicas.
Si va a ser útil en el mundo real, la IA tiene que ser capaz de inferir rápidamente. Y esto es cada vez más importante a medida que las aplicaciones se vuelven más complejas y manejan cantidades de datos cada vez mayores.
NVIDIA ha anunciado hoy en su blog que TensorRT 8 es capaz de reducir el tiempo de inferencia a la mitad en comparación con la versión anterior del software, lo que significa que puede utilizarse para desarrollar motores de búsqueda de alto rendimiento, sistemas de recomendación de anuncios y chatbots que pueden desplegarse en la nube o en el borde de la red.
Esto es gracias a algunas optimizaciones del transformador en TensorRT 8, que según NVIDIA ofrecen «una velocidad récord para las aplicaciones de lenguaje». El nuevo software puede, por ejemplo, ejecutar BERT-Large, uno de los modelos basados en transformadores más utilizados del mundo, en sólo 1,2 milisegundos, dijo NVIDIA. Anteriormente, los investigadores de IA tenían que reducir el tamaño de su modelo para ejecutar BERT-Large a esta velocidad, pero al hacerlo obtenían resultados menos precisos. Con TensorRT 8, es posible duplicar o triplicar el tamaño de un modelo de IA y, aun así, conseguir mejoras espectaculares en la precisión, afirma la compañía.
BERT (Bidirectional Encoder Representations from Transformers) es un modelo de procesamiento del lenguaje natural propuesto por investigadores de Google Research en 2018. Cuando se propuso, logró una precisión de vanguardia en muchas tareas de PNL y NLU, como por ejemplo Evaluación de comprensión del lenguaje general.
Greg Estes, vicepresidente de programas para desarrolladores de NVIDIA, afirmó que los modelos de IA están aumentando exponencialmente su complejidad. Al mismo tiempo, está aumentando la demanda mundial de aplicaciones en tiempo real que utilizan la IA. «La última versión de TensorRT introduce nuevas capacidades que permiten a las empresas ofrecer aplicaciones de IA conversacional a los clientes con un nivel de calidad y capacidad de respuesta que nunca antes había sido posible», dijo.
La nueva versión de TensorRT aporta dos nuevas características clave que también aceleran el rendimiento de la inferencia de la IA. Se trata de una técnica denominada sparsity que permite aumentar la eficiencia de las unidades de procesamiento gráfico NVIDIA Ampere, de modo que los desarrolladores pueden acelerar las redes neuronales reduciendo las operaciones de cálculo que realizan esos chips.
Otra novedad es el llamado entrenamiento consciente de la cuantización, que permite a los desarrolladores utilizar modelos entrenados para ejecutar la inferencia en la precisión INT8, sin perder precisión. Según la empresa, esto reduce significativamente la sobrecarga de cálculo y almacenamiento, lo que permite que los núcleos tensoriales trabajen de forma más eficiente.
NVIDIA dijo que TensorRT 8 ya está disponible de forma general y será gratuito para todos los miembros del Programa de Desarrolladores de NVIDIA. Las nuevas versiones de los plug-ins, parsers y muestras de TensorRT 8 están disponibles a través de una licencia de código abierto a través del repositorio GitHub de TensorRT.
📬 Newsletter gratuito