
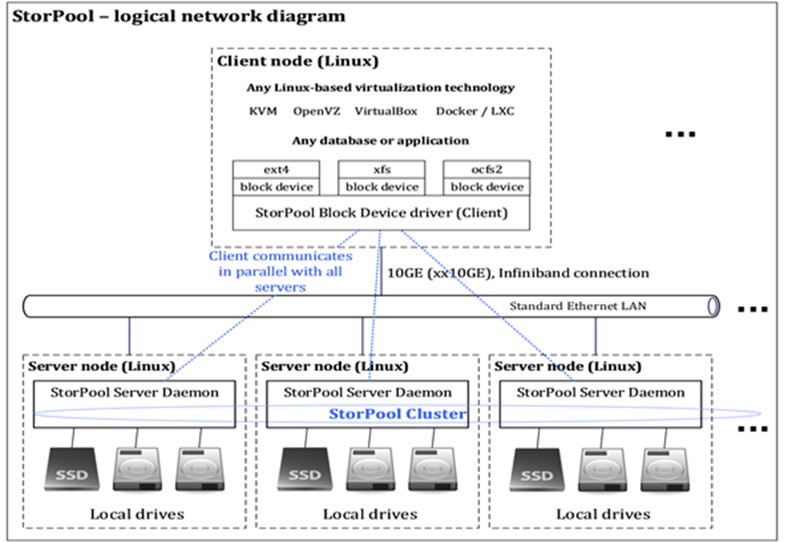
StorPool es un software de almacenamiento distribuido que “virtualiza” el almacenamiento agregando el rendimiento y la capacidad de las unidades colocadas en servidores estándar. StorPool crea un conjunto común de almacenamiento compartido entre todas las unidades.
StorPool reemplaza directamente las redes de área de almacenamiento (SAN). El almacenamiento en bloque que proporciona es altamente fiable, escalable y de alto rendimiento. Para conseguir estos resultados usamos los servidores estándar x86. Los datos son “trozados” y las copias se distribuyen entre un número previamente determinado de servidores o racks. De esta manera se consiguen muchas ventajas – alta fiabilidad, alto rendimiento, tiempos de recuperación más rápidos, etc.
¿Qué hace a StorPool mejor que el resto del software de almacenamiento de datos?
StorPool permite soluciones de infraestructura convergente/integrada, también conocida como híper-convergencia. Con la ayuda de StorPool los clientes pueden computar (máquinas virtuales, aplicaciones, bases de datos, etc.) en los mismos servidores que StorPool (almacenamiento). StorPool es un software de máxima eficiencia que ocupa una parte mínima de los recursos de cada servidor, dejando cuantiosos recursos para la ejecución de otras aplicaciones, sumadas a las que ya se están ejecutando. Esta convergencia entre las cargas de almacenamiento y computación ayuda a los clientes a alcanzar niveles sin precedentes de utilización, reduciendo significativamente al mismo tiempo el coste total de propiedad y, por lo tanto, aumentando el retorno de la inversión.
StorPool es una herramienta muy potente de virtualización del almacenamiento en la que la redundancia está garantizada a través de replicaciones síncronas. Para hacernos una buena idea de qué es lo que hace StorPool podríamos compararlo con un software muy avanzado RAID (conjunto redundante de discos independientes) entre los servidores y racks. La consistencia es garantizada por la verificación de integridad de los datos. Normalmente los datos que un cliente de StorPool necesita se encuentran en las unidades ubicadas en todos los servidores del clúster. Este diseño provee un alto rendimiento y balanceo de carga en tiempo real. La ubicación y la replicación de los datos son ajustables de forma independiente para cada uno de los volúmenes.
| Póngase en contacto con nosotros |
—
Ilustración: Thumbs up por © Vgstudio vía Shutterstock